数据的清理与校检是进行数据分析与市场研究的前提和基础。
从市场上调查而来的数据,以各种变量形式存在,这些变量从内容上看大致可以分为两类:客观变量与主观变量。客观变量是指分析单位的属性、状态和行为,如性别、年龄等具有确定性、稳定性、对应性特征的数据。客观变量的清理与校检可以通过设置变量之间的逻辑检验进行查错。如个人年收入应小于家庭年收入,各项消费支出应小于总收入等其他与生活规则、社会常识、行为习惯相一致的变量关系。主观变量是指受访者的态度、满意度等其他主观感受,这些变量具有一定的随机性、可变性与不可预测性,由于主观变量与其他变量之间是概率性关系,而不是明确的对应性关系,因此主观变量的逻辑检验不容易直接设置变量关系进行查错。也正是基于此,研究者在实际操作中往往忽略主观数据的逻辑查错。从研究的角度讲,这是不科学的。
另一方面,目前的市场调查、民意调查中涉及的主观变量日渐增多。如产品的满意度调查、产品测试、政府的民意监测等等。因此,如何进行主观数据的逻辑查错,提高数据质量是摆在研究者面前的一个重要任务。
方差法
在量表题中,假如受访者选的都是同一个答案,即各个项目的方差为0,那么我们就有理由怀疑受访者的填答质量。以5级量表题为例,由于中国传统的“中庸”思想,受访者在调查中往往容易选择“3”,即问题的中间状况;或者由于被访者填答不认真,胡乱作答,从而统一在某个选项上作答。虽然,这并不排除这有可能是受访者的真实意见,但这种概率是很小的,因此我们通常可以选择剔除这些问卷。当然方差为0只是极端情况,研究者可以根据数据结构、研究内容等确定合理的剔除标准。
为了避免上述受访者作弊行为的发生,在问卷设计中,我们应注意两点:1.在量表题中,避免单向度的提问,尽量从正反两个方面进行测试,避免受访者的“顺从式”作答。2.考虑采取4级或6级量表进行测试,避免5级量表中出现的中间状态,从而迫使受访者做出正面或反面的判断。
内容法
内容法主要是指研究人员基于研究经验,根据题目中选项内容上的逻辑关系(如包含关系、排斥关系等),而对数据结果作出的判断。
例如,在某汽车品牌项目中,我们要求受访者(该品牌的实际用户)用1~10分对某汽车品牌的总体满意度和该品牌汽车在各个具体方面的表现分别打分,1分表示很不满意,10分表示非常满意。分数越低,表示越不满意。要求受访者打分的内容如表1所示:
表1 受访者打分内容
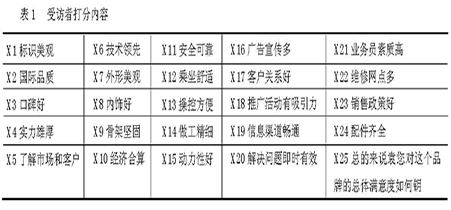
我们假设X1-X24包含的内容已经囊括了该汽车品牌满意度的所有方面,因此根据现实经验,X1-X24的得分不能全部小于5。同时,X1-X20的均值与X25(总体满意度)的得分差距不能超过3.5分。
应该说,应用“内容法”判断数据结果是具有一定危险性的,但是如果研究是建立在成熟的模型基础之上,并且各项指标具有较高的效度,那么应用该方法是可行的。
因子分析法
在市场测试或民意调查中,受访者的有些行为和态度具有明显的社会赞许倾向性属性,对这些行为和态度的研究容易导致应答偏倚,即人们对问题的回答容易受社会期望的影响。社会规范规定了什么样的行为、态度和观点为社会所提倡,被人们所称道。这样如果所陈述的行为、态度和观点为社会所提倡,就会使被试倾向于作出回答“是”;否则,则答“否”。由于个体寻求赞许性的动机而形成的偏倚称之为赞许性偏倚。
为了评估受访者的行为和态度是否受社会赞许动机的影响,可以在问卷中使用社会赞许性量表。这种量表有很多,下面列出一种由Crowne和Marlowe研制,由杨国枢汉化为中文问卷的量表。
附社会赞许量表
下面的句子都是有关个人情形的描述。请仔细阅读每个句子,然后判断该语句所描述的是否符合您自己的真实情形。如果您的实际情形确如该语句所说,那么就在被选答案的“是”上打个“√”记号;如果您的实际情形并非如该语句所说,那么就在被选答案的“否”上打个“√”记号。
1.当您不知道某些事情的时候,您会毫不介意自己的无知。(1)是(2)否
2.有时你会占别人的便宜。(1)是(2)否
3.当你犯了过错时,你总会勇于认错。(1)是(2)否
4.你有时非常嫉妒别人的好运气。(1)是(2)否
5.有时你喜欢讲别人的闲话。(1)是(2)否
6.你从来不会想到让别人代你受过。(1)是(2)否
7.有时你宁可以牙还牙,也不愿意原谅别人。(1)是(2)否
8.你有时很想打开别人的信偷看一下。(1)是(2)否
评估所测行为或态度是否受社会赞许性动机的影响,通过因子分析的方法来实施,具体做法是看这些行为或态度是否与社会赞许项目归于一个因子,如果是,则提示该行为测量有问题;而如果测量行为被归于其余因子上,并且负荷值很高,提示受社会赞许反映倾向影响很少。对于个体总体应答的评价应用社会赞许量表测量得分来判断每个应答者受社会赞许反映倾向的影响大小,如果某人的得分超过了一定的范围,这时就对可以其所提供的信息的真实性产生怀疑。
相关系数法
相关系数法是指依据数据结果,从总体上得出各主观变量之间的数量关系,然后以此判断出数据库中存在的值得怀疑的数据。下面以某居民生活质量调查中涉及的一道态度量表题(采用5级量表编制)为例,说明相关系数法的应用。该数据来源于北京某知名咨询公司于2005年10月对全国8个大中城市、7个小城镇及8个农村地区进行的入户调查,成功样本量为4128个。
首先我们计算出各项目之间的Spearman相关系数,其相关系数矩阵见表2。
表2 Spearman相关矩阵
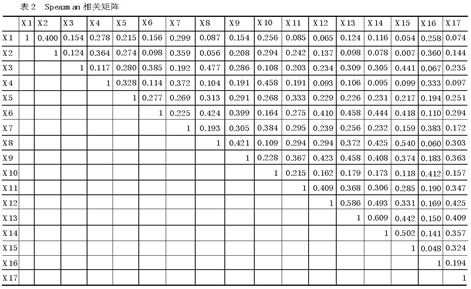
其次,我们以其Spearman相关系数的绝对值是否大于等于0.3作为两个变量是否相关的标准,因此相关系数的矩阵表可以转换为下列简易形式(表3)。
表3 转换后的相关矩阵
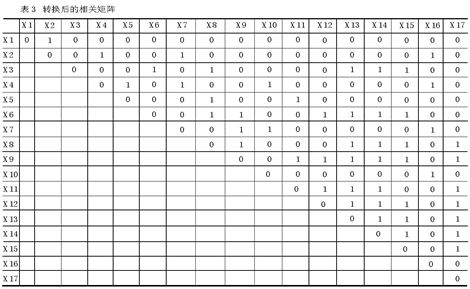
从表3中可以看出,该量表包含的17个变量中共有50个相关对。由于变量只能在1、2、3、4、5之内取值,因此如果两个变量呈现正相关关系的话,那么这两个变量的取值应该比较接近,但是假如出现某个相关对(x,y)一个变量取最大值,另一个变量取最小值这种极端情况,那么我们就有理由怀疑,受访者在胡乱作答,因为这种情况违反了正相关原理。我们就可以把这一数对鉴定为异常对。同样地,如果两个变量呈现负相关的话,异常对则是某一个数对(x,y)中,x和y的取值完全相同。
最后,根据该原则,我们统计出各变量之间出现的异常对情况。如表四所示。
表4 各变量的异常对情况
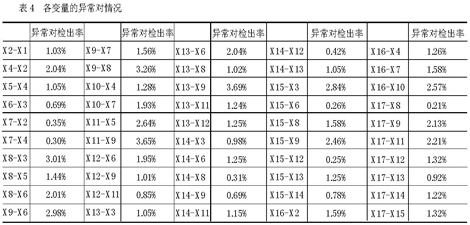
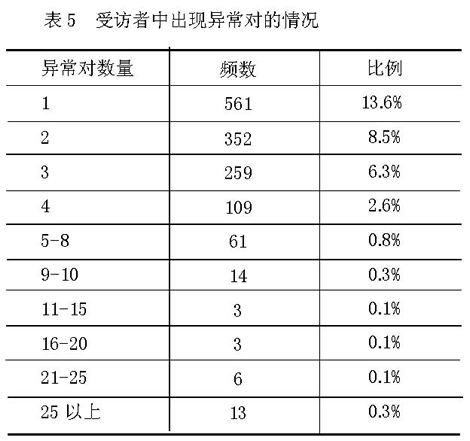
我们认为,如果受访者在某一相关对上表现为异常,我们并不能说该受访者的作答违背了题目的内在逻辑,但是,如果某一受访者在该量表题中表现出较多的异常对,我们就有理由对该受访者的作答质量提出怀疑。我们统计出了居民态度量表中的受访者中出现异常对的情况(表5)。从表中可以看出共有13份问卷出现了25对以上的异常对,即在50对相关对中有一半以上出现了异常。因此这些受访者的资料应该引起我们的注意。
表5 受访者中出现异常队的情况
值得注意的是,由于主观数据之间的概率性关系,我们不能简单地凭借某一种检验方法就认定某条数据是错误的,而需要进行多角度、全方位的检验与论证,以保证获得更为真实和科学的数据。因此,上述三种主观数据的校检方法是互相联系、互相印证、互相补充的。